What are heuristic, feature-based, and E2E models in machine learning
Structured data is a term used for any data that resides in a fixed field within a record or file, two such examples being relational databases and spreadsheets. In day-to-day life, structured data is also the most common type of data available to businesses, and most machine learning problems that need to be solved in finance deal with structured data in one way or another.
In this article we will look at various machine learning models used to solve common financial problems such as heuristic, feature based and E2E models.
This article is taken from the book, Machine Learning for Finance, by Packt Publishing, written by Jannes Klaas. This book, explores new advances in machine learning and shows how they can be applied across the financial sector, including insurance, transactions, and lending.
let's take a second to pause and ponder over the different kinds of models we could build.
- A heuristic-based model is a simple "rule of thumb" developed purely by humans. Usually, the heuristic model stems from having an expert knowledge of the problem.
- A feature-based model relies heavily on humans modifying the data to create new and meaningful features, which are then fed into a (simple) machine learning algorithm. This approach mixes expert knowledge with learning from data.
- An E2E model learns purely from raw data. No human expertise is used, and the model learns everything directly from observations.
In our case, a heuristic-based model could be created to mark all transactions with the TRANSFER transaction type and an amount over $200,000 as fraudulent. Heuristic-based models have the advantage that they are both fast to develop and easy to implement; however, this comes with a pay-off, their performance is often poor, and fraudsters can easily play the system. Let's imagine that we went with the preceding heuristic-based model, fraudsters transferring only $199,999, under the fraudulent limit, would evade detection.
An important heuristic in the field of trading is the momentum strategy. Momentum strategies involve betting that a stock that's on the rise will continue to rise, with people then buying that stock. While this strategy sounds too simple to be any good, it is in fact, a reasonably successful strategy that many high-frequency trading and quantitative outlets are using today.
To create features, experts craft indicators that can distinguish fraudulent transactions from those that are genuine. This is often done using statistical data analysis, and when compared to the heuristic-based model that we proposed early on, it will take longer, but with the benefit of better results.
Feature engineering-based models are a midway between data and humans shaping rules, where human knowledge and creativity are exploited to craft good features, and data and machine learning are used to create a model from those features.
E2E models learn purely from collected data without using expert knowledge. As discussed before, this often yields much better results, but at the cost of taking a lot of time to complete. This method also has some additional elements worth considering. For instance, collecting the large amount of data that will be needed is an expensive task, as humans have to label millions of records.
Many people in the industry right now take the view that shipping a poor model is often better than not shipping anything at all. After all, having some protection against fraud is better than simply having none.
Using a heuristic approach that lets through half of all fraudulent transactions is better than having no fraud detection at all. The graph shows us the performance of the three models we introduced earlier on, against the time taken to implement them.
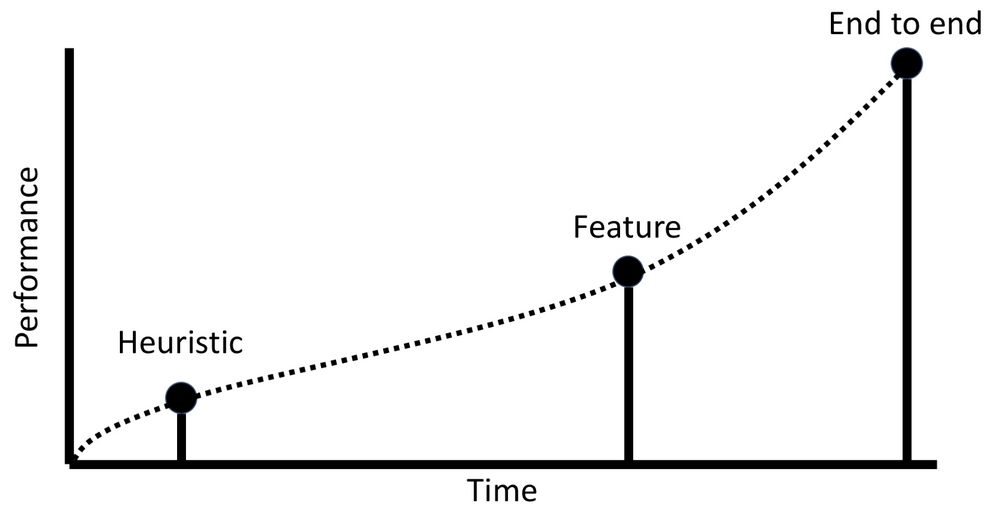
The methods used and the performance of the system during development
The best method is to use a combination of all three. If we deploy a heuristic model that meets the basic requirements of the task that it set out to achieve, then it can be shipped. By employing this method, the heuristic then becomes the baseline that any other approach has to beat. Once your heuristic model is deployed, then all your efforts should then be directed toward building a feature-based model, which as soon as it beats the initially deployed heuristic model, can then be deployed while you continue to refine the model.
As we've discussed before, feature-based models often deliver pretty decent performance on structured data tasks; this gives companies the time to undertake the lengthy and expensive task of building an E2E model, which can be shipped once it beats the feature-based model.
To conclude, we explained various types of machine learning models namely - heuristic, feature based and end to end model, to solve common financial problems.
This post is a part of the book, Machine Learning for Finance, by Packt Publishing, written by Jannes Klaas. Check out this book to know more about how these models can be implemented to your software as the book systematically explains how machine learning works on structured data, text, images, and time series.