Python Projects: Site emails from a specified URL
Python Web Project-8 with Solution
Create a Python project to get the site emails from a specified URL.
Sample Output:
url -> https://github.com 2 emails found: [email protected] [email protected]
Sample Solution:
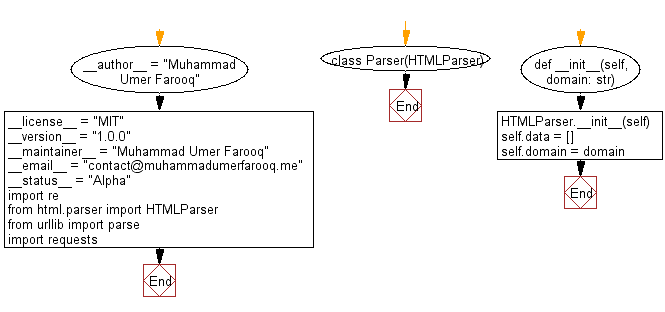
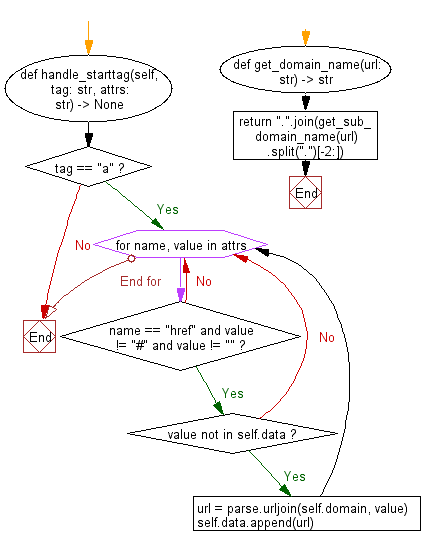
Python Code:
"""Get the site emails from URL."""
#Source:https://bit.ly/3o9yYFu
__author__ = "Muhammad Umer Farooq"
__license__ = "MIT"
__version__ = "1.0.0"
__maintainer__ = "Muhammad Umer Farooq"
__email__ = "[email protected]"
__status__ = "Alpha"
import re
from html.parser import HTMLParser
from urllib import parse
import requests
class Parser(HTMLParser):
def __init__(self, domain: str):
HTMLParser.__init__(self)
self.data = []
self.domain = domain
def handle_starttag(self, tag: str, attrs: str) -> None:
"""
This function parse html to take takes url from tags
"""
# Only parse the 'anchor' tag.
if tag == "a":
# Check the list of defined attributes.
for name, value in attrs:
# If href is defined, and not empty nor # print it.
if name == "href" and value != "#" and value != "":
# If not already in data.
if value not in self.data:
url = parse.urljoin(self.domain, value)
self.data.append(url)
# Get main domain name (example.com)
def get_domain_name(url: str) -> str:
"""
This function get the main domain name
>>> get_domain_name("https://a.b.c.d/e/f?g=h,i=j#k")
'c.d'
>>> get_domain_name("Not a URL!")
''
"""
return ".".join(get_sub_domain_name(url).split(".")[-2:])
# Get sub domain name (sub.example.com)
def get_sub_domain_name(url: str) -> str:
"""
>>> get_sub_domain_name("https://a.b.c.d/e/f?g=h,i=j#k")
'a.b.c.d'
>>> get_sub_domain_name("Not a URL!")
''
"""
return parse.urlparse(url).netloc
def emails_from_url(url: str = "https://github.com") -> list:
"""
This function takes url and return all valid urls
"""
# Get the base domain from the url
domain = get_domain_name(url)
# Initialize the parser
parser = Parser(domain)
try:
# Open URL
r = requests.get(url)
# pass the raw HTML to the parser to get links
parser.feed(r.text)
# Get links and loop through
valid_emails = set()
for link in parser.data:
# open URL.
# read = requests.get(link)
try:
read = requests.get(link)
# Get the valid email.
emails = re.findall("[a-zA-Z0-9]+@" + domain, read.text)
# If not in list then append it.
for email in emails:
valid_emails.add(email)
except ValueError:
pass
except ValueError:
exit(-1)
# Finally return a sorted list of email addresses with no duplicates.
return sorted(valid_emails)
if __name__ == "__main__":
emails = emails_from_url("https://github.com")
print(f"{len(emails)} emails found:")
print("\n".join(sorted(emails)))
Flowchart:
Go to:
Improve this sample solutions and post your code through Disqus