Fetching data asynchronously from multiple URLs using Python async IO
4. Concurrent URL Fetcher
Write a Python program that implements a coroutine to fetch data from two different URLs simultaneously using the "aiohttp" library.
Sample Solution:
Code:
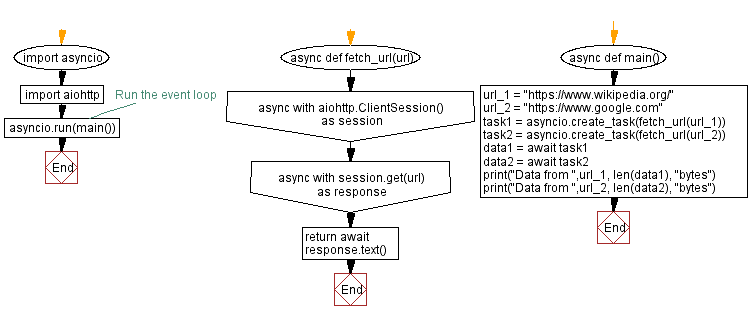
import asyncio
import aiohttp
async def fetch_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
async def main():
url_1 = "https://www.wikipedia.org/"
url_2 = "https://www.google.com"
task1 = asyncio.create_task(fetch_url(url_1))
task2 = asyncio.create_task(fetch_url(url_2))
data1 = await task1
data2 = await task2
print("Data from ",url_1, len(data1), "bytes")
print("Data from ",url_2, len(data2), "bytes")
# Run the event loop
asyncio.run(main())
Output:
Data from https://www.wikipedia.org/ 74154 bytes Data from https://www.google.com 18273 bytes
Explanation:
In the above exercise-
- The "fetch_url()" function coroutine is defined to asynchronously fetch data from a given URL using the 'aiohttp' library. It uses an aiohttp.ClientSession() to manage the HTTP requests and responses. The 'async' with syntax ensures that the session is properly closed.
- The main coroutine is defined to run asynchronous operations. It creates two tasks using asyncio.create_task() that execute the fetch_url coroutine concurrently for two different URLs.
- The 'await' keyword is used to wait for the completion of each task, storing the fetched data in data1 and data2.
- Finally, the program prints the size of the fetched data from both URLs.
Flowchart:
For more Practice: Solve these Related Problems:
- Write a Python program that uses aiohttp to asynchronously fetch data from two different URLs and prints the status code of each response.
- Write a Python script to define a coroutine that concurrently retrieves content from two URLs using aiohttp, then prints the lengths of the responses.
- Write a Python function that concurrently fetches JSON data from two URLs with aiohttp, merges the results, and prints the combined data.
- Write a Python program to implement two asynchronous functions using aiohttp that fetch data from separate endpoints concurrently, then log the time taken for both requests.
Go to:
Previous: Printing numbers with a delay using asyncio coroutines in Python.
Next: Measuring total execution time of concurrent asynchronous tasks in Python.
Python Code Editor :
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.