Pandas SQL Query: Select distinct department id from employees file
4. Select Distinct Department IDs from DEPARTMENTS File
Write a Pandas program to select distinct department id from employees file.
DEPARTMENTS.csv
Sample Solution :
Python Code :
import pandas as pd
employees = pd.read_csv(r"EMPLOYEES.csv")
departments = pd.read_csv(r"DEPARTMENTS.csv")
job_history = pd.read_csv(r"JOB_HISTORY.csv")
jobs = pd.read_csv(r"JOBS.csv")
countries = pd.read_csv(r"COUNTRIES.csv")
regions = pd.read_csv(r"REGIONS.csv")
locations = pd.read_csv(r"LOCATIONS.csv")
print("Distinct department_id:")
print(employees.department_id.unique())
Sample Output:
Distinct department_id: [ 90. 60. 100. 30. 50. 80. nan 10. 20. 40. 70. 110.]
Equivalent SQL Syntax:
SELECT DISTINCT department_id FROM EMPLOYEES;
Click to view the table contain:
For more Practice: Solve these Related Problems:
- Write a Pandas program to extract and display unique department_id values from DEPARTMENTS.csv.
- Write a Pandas program to count the number of distinct department_id values in DEPARTMENTS.csv.
- Write a Pandas program to extract distinct department_ids, sort them, and display the sorted list.
- Write a Pandas program to filter DEPARTMENTS.csv for department_ids above a specific value and then display the unique results.
Go to:
PREV : Extract First 7 Records from EMPLOYEES File.
NEXT : Employee Names & Dept No. for Last Name "McEwen".
Python Code Editor:
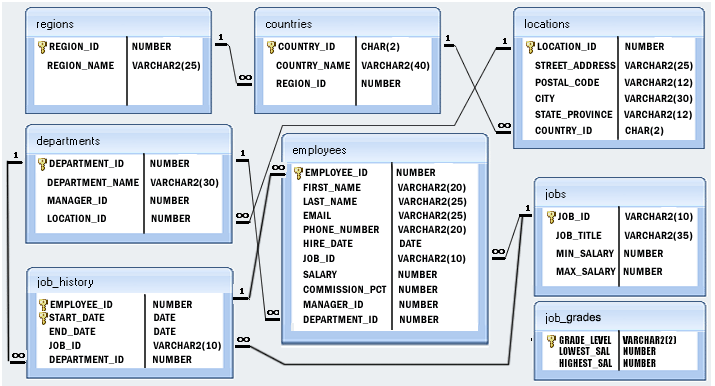
Structure of HR database :
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
What is the difficulty level of this exercise?