SQL Exercise: In ASC order, list managers and count their employees
[An editor is available at the bottom of the page to write and execute the scripts.]
96. From the following table, write a SQL query to create a list of the managers and the number of employees they supervise. Sort the result set in ascending order on manager. Return manager ID and number of employees under them.
Sample table: employees
+-------------+-------------+-------------+----------+--------------------+------------+------------+----------+----------------+------------+---------------+ | EMPLOYEE_ID | FIRST_NAME | LAST_NAME | EMAIL | PHONE_NUMBER | HIRE_DATE | JOB_ID | SALARY | COMMISSION_PCT | MANAGER_ID | DEPARTMENT_ID | +-------------+-------------+-------------+----------+--------------------+------------+------------+----------+----------------+------------+---------------+ | 100 | Steven | King | SKING | 515.123.4567 | 2003-06-17 | AD_PRES | 24000.00 | 0.00 | 0 | 90 | | 101 | Neena | Kochhar | NKOCHHAR | 515.123.4568 | 2005-09-21 | AD_VP | 17000.00 | 0.00 | 100 | 90 | | 102 | Lex | De Haan | LDEHAAN | 515.123.4569 | 2001-01-13 | AD_VP | 17000.00 | 0.00 | 100 | 90 | | 103 | Alexander | Hunold | AHUNOLD | 590.423.4567 | 2006-01-03 | IT_PROG | 9000.00 | 0.00 | 102 | 60 | | 104 | Bruce | Ernst | BERNST | 590.423.4568 | 2007-05-21 | IT_PROG | 6000.00 | 0.00 | 103 | 60 | | 105 | David | Austin | DAUSTIN | 590.423.4569 | 2005-06-25 | IT_PROG | 4800.00 | 0.00 | 103 | 60 | | 106 | Valli | Pataballa | VPATABAL | 590.423.4560 | 2006-02-05 | IT_PROG | 4800.00 | 0.00 | 103 | 60 | | 107 | Diana | Lorentz | DLORENTZ | 590.423.5567 | 2007-02-07 | IT_PROG | 4200.00 | 0.00 | 103 | 60 | | 108 | Nancy | Greenberg | NGREENBE | 515.124.4569 | 2002-08-17 | FI_MGR | 12008.00 | 0.00 | 101 | 100 | | 109 | Daniel | Faviet | DFAVIET | 515.124.4169 | 2002-08-16 | FI_ACCOUNT | 9000.00 | 0.00 | 108 | 100 | ......... | 206 | William | Gietz | WGIETZ | 515.123.8181 | 2002-06-07 | AC_ACCOUNT | 8300.00 | 0.00 | 205 | 110 | +-------------+-------------+-------------+----------+--------------------+------------+------------+----------+----------------+------------+---------------+
Sample Solution:
SELECT w.manager_id,
count(*)
FROM employees w,
employees m
WHERE w.manager_id = m.emp_id
GROUP BY w.manager_id
ORDER BY w.manager_id ASC;
Sample Output:
manager_id | count
------------+-------
65646 | 2
66928 | 5
67832 | 1
67858 | 1
68319 | 3
69062 | 1
(6 rows)
Explanation:
The said query in SQL that retrieves the manager ID along with the number of employees who report to each manager from the 'employees' table.
This creates a self-join, where each row in the 'employees' table is compared with every other row in the same table to identify which employees report to each manager.
The WHERE clause filters the rows where the manager ID of the 'employees' table aliased as "w" matches the employee ID of the 'employees' table aliased as "m", indicating that the employee in the "w" row reports to the manager in the "m" row.
The GROUP BY clause groups the results by the manager ID, so that the count of employees can be calculated for each manager and the ORDER BY clause sorts the results in ascending order by the manager ID.
Relational Algebra Expression:

Relational Algebra Tree:
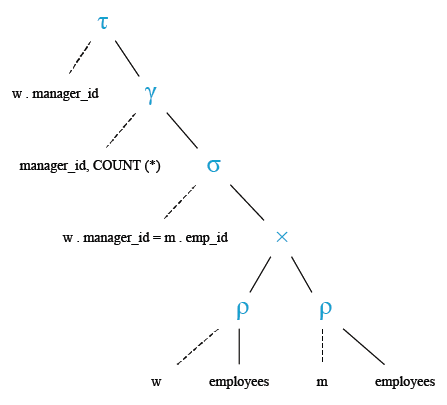
Go to:
PREV : List employees salary within min_salary and max_salary.
NEXT : Number of employee for each job in each department.
Practice Online
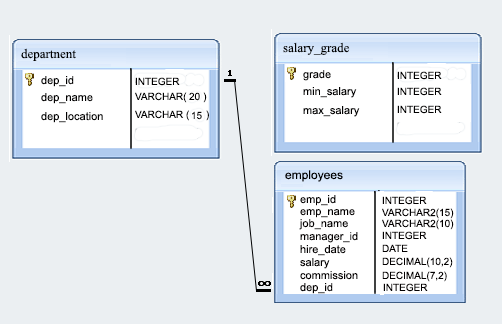
Sample Database: employees
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.