SQL Self Join
What is Self Join in SQL?
A self join is a join in which a table is joined with itself (which is also called Unary relationships), especially when the table has a FOREIGN KEY which references its own PRIMARY KEY. To join a table itself means that each row of the table is combined with itself and with every other row of the table. This allows the table to establish a relationship between its rows, such as an employee-supervisor relationship within an organization's employee table.
The self join can be viewed as a join of two copies of the same table. The table is not actually copied, but SQL performs the command as though it were.
Key Characteristics of Self Joins
- Same Table Used Twice: The table is conceptually duplicated, and each instance is given an alias to differentiate them within the query.
- Aliases for Clarity: Since the table is referred to twice, aliases are crucial to distinguish between the two instances in the query.
- Hierarchical Data Representation: Self joins are commonly used to represent hierarchical data, such as organizational structures or recursive relationships.
Syntax:
The syntax for a self join closely resembles that of a regular join. The critical difference is that the same table is used twice, and aliases are applied to differentiate between the two instances. Table name aliases are defined in the FROM clause of the SELECT statement.
SELECT a.column_name, b.column_name... FROM table1 a, table1 b WHERE a.common_filed = b.common_field;
Here’s a breakdown:
- Aliases (a, b): They are used to distinguish the table instances.
- Common Field: This is the column that relates the rows within the table, often a foreign key referring to the primary key.
For this tutorial we have used a table EMPLOYEE, that has one-to-many relationship.
Code to create the table EMPLOYEE
SQL Code:
CREATE TABLE employee(emp_id varchar(5) NOT NULL,
emp_name varchar(20) NULL,
dt_of_join date NULL,
emp_supv varchar(5) NULL,
CONSTRAINT emp_id PRIMARY KEY(emp_id) ,
CONSTRAINT emp_supv FOREIGN KEY(emp_supv)
REFERENCESemployee(emp_id));
The structure of the table
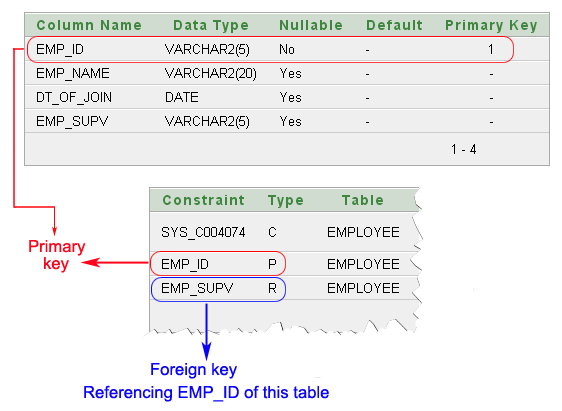
In the EMPLOYEE table displayed above, emp_id is the primary key. emp_supv is the foreign key (this is the supervisor’s employee id).
If we want a list of employees and the names of their supervisors, we’ll have to JOIN the EMPLOYEE table to itself to get this list.
Unary relationship to employee
How the employees are related to themselves:
- An employee may report to another employee (supervisor).
- An employee may supervise himself (i.e. zero) to many employees (subordinates).
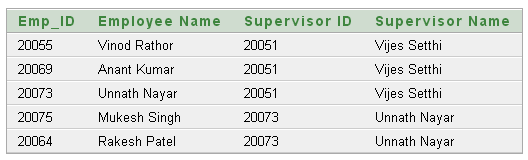
We have the following data into the table EMPLOYEE.

The above data shows:
- Unnath Nayar's supervisor is Vijes Setthi
- Anant Kumar and Vinod Rathor can also report to Vijes Setthi.
- Rakesh Patel and Mukesh Singh are under supervison of Unnith Nayar.
Example of SQL SELF JOIN
In the following example, we will use the table EMPLOYEE twice and in order to do this we will use the alias of the table.
To get the list of employees and their supervisor the following SQL statement has used:
SQL Code:
-- Selecting specific columns: 'emp_id' and 'emp_name' from table 'a' (employee), and 'emp_id' and 'emp_name' from table 'b' (also employee)
SELECT a.emp_id AS "Emp_ID", a.emp_name AS "Employee Name", b.emp_id AS "Supervisor ID", b.emp_name AS "Supervisor Name"
-- Performing a self-join on the 'employee' table, aliasing the first instance as 'a' and the second instance as 'b'
FROM employee a, employee b
-- Defining the join condition where 'a.emp_supv' (employee's supervisor ID) equals 'b.emp_id' (supervisor's ID)
WHERE a.emp_supv = b.emp_id;
Explanation:
- This SQL query performs a self-join on the 'employee' table to retrieve information about employees and their supervisors.
- It selects specific columns from the table, aliasing the table instances as 'a' and 'b' for clarity.
- The columns selected include 'emp_id' and 'emp_name' from both instances, representing both employees and their supervisors.
- The WHERE clause defines the join condition, specifying that 'a.emp_supv' (employee's supervisor ID) must match 'b.emp_id' (supervisor's ID). This establishes the relationship between employees and their supervisors.
- By performing this self-join, the query retrieves information about each employee and their corresponding supervisor.
- This query is useful for analyzing hierarchical relationships within the organization, such as identifying supervisors for each employee.
Output:
Output of the said SQL statement shown here is taken by using Oracle Database 10g Express Edition.
Advantages of Using Self Joins
- Hierarchical Data Retrieval: Self joins are particularly effective for retrieving hierarchical data, such as organizational structures.
- Simplified Queries: They simplify complex hierarchical queries by using standard SQL join operations.
- Enhanced Data Analysis: Self joins allow for deep insights into relationships within the same dataset, such as analyzing reporting structures.
Performance Implications
- Indexes: Ensure that appropriate indexes are used, especially on foreign key columns, to optimize the performance of self joins.
- Large Datasets: With very large tables, self joins can become computationally intensive. Consider using strategies such as indexing, partitioning, or restructuring data.
Frequently Asked Questions (FAQ) - SQL Self Join
1. What is a Self Join in SQL?
A self join is a type of join where a table is joined with itself. This is particularly useful for tables that have a foreign key referencing their own primary key, enabling relationships like employee-supervisor hierarchies within the same table.
2. How does a Self Join work?
A self join involves combining rows from the same table as though the table were duplicated. SQL performs this operation using table aliases to differentiate between the two instances of the same table.
3. When should we use a Self Join?
Use a self join when we need to represent or analyze hierarchical relationships within a single table. Common scenarios include organizational structures, where each employee might report to another employee within the same table.
4. What are the key characteristics of Self Joins?
- Same Table Used Twice: The table is conceptually used twice, with each instance distinguished by aliases.
- Aliases for Clarity: Aliases help differentiate between the two instances of the table in the query.
- Hierarchical Data Representation: Ideal for representing and querying hierarchical data structures.
5. Why are aliases important in Self Joins?
Aliases are crucial because they differentiate the two instances of the same table in the query. Without aliases, it would be unclear which instance of the table a column refers to.
6. What are the advantages of using Self Joins?
- Hierarchical Data Retrieval: They efficiently retrieve hierarchical data, such as organizational structures.
- Simplified Queries: Self joins simplify queries involving hierarchical relationships by using standard SQL join syntax.
- Enhanced Data Analysis: They provide deep insights into relationships within the same dataset.
7. What are the performance implications of using Self Joins?
- Indexes: Appropriate indexes on foreign key columns can significantly improve performance.
- Large Datasets: Self joins can be computationally intensive on large datasets. Consider strategies like indexing, partitioning, or data restructuring to optimize performance.
8. Can Self Joins be used with large datasets?
Yes, but caution is needed. Self joins on large datasets can be resource-intensive. Optimizing performance through indexing, partitioning, and data restructuring is recommended.
See also:
Check out our 1000+ SQL Exercises with solution and explanation to improve your skills.
PREV : Join a table to itself
NEXT : Joining tables through referential integrity