NumPy: numpy.loadtxt() function
numpy.loadtxt() function
The numpy.loadtxt() function is used to load data from a text file into a numpy array. Each row in the text file must have the same number of values. This function can handle a wide range of text file formats and can skip comments and header rows.
Syntax:
numpy.loadtxt(fname, dtype=<class 'float'7gt;, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes')
Parameters:
| Name | Description | Required / Optional |
|---|---|---|
| fname | File, filename, or generator to read. If the filename extension is .gz or .bz2, the file is first decompressed. Note that generators should return byte strings for Python 3k | Required |
| dtype | Data-type of the resulting array; default: float. If this is a structured data-type, the resulting array will be 1-dimensional, and each row will be interpreted as an element of the array. In this case, the number of columns used must match the number of fields in the data-type. | Optional |
| comments | The characters or list of characters used to indicate the start of a comment. None implies no comments. For backwards compatibility, byte strings will be decoded as 'latin1'. The default is '#'. | Optional |
| delimiter | The string used to separate values. For backwards compatibility, byte strings will be decoded as ‘latin1’. The default is whitespace. | Optional |
| converters | A dictionary mapping column number to a function that will parse the column string into the desired value. E.g., if column 0 is a date string: converters = {0: datestr2num}. Converters can also be used to provide a default value for missing data (but see also genfromtxt): converters = {3: lambda s: float(s. strip() or 0)}. Default: None. | optional |
| skiprows | Skip the first skiprows lines; default: 0 | optional |
| usecols | Which columns to read, with 0 being the first. For example, usecols = (1,4,5) will extract the 2nd, 5th and 6th columns. The default, None,results in all columns being read. Changed in version 1.11.0: When a single column has to be read it is possible to use an integer instead of a tuple. E.g usecols = 3 reads the fourth column the same way as usecols = (3,) would |
optional |
| unpack | If True, the returned array is transposed, so that arguments may be unpacked using x, y, z = loadtxt(...). When used with a structured data-type, arrays are returned for each field. Default is False. | optional |
| ndmin | The returned array will have at least ndmin dimensions. Otherwise monodimensional axes will be squeezed. Legal values: 0 (default), 1 or 2. New in version 1.6.0. | optional |
| encoding | Encoding used to decode the inputfile. Does not apply to input streams. The special value 'bytes' enables backward compatibility workarounds that ensures you receive byte arrays as results if possible and passes 'latin1' encoded strings to converters. Override this value to receive unicode arrays and pass strings as input to converters. If set to None the system default is used. The default value is 'bytes'. New in version 1.14.0. | optional |
Return value:
[ndarray]
Data read from the text file
Example: Loading data from a text file using numpy.loadtxt()
>>> import numpy as np
>>> from io import StringIO
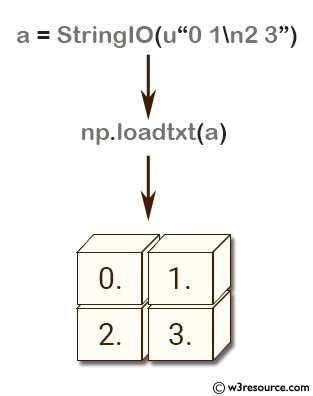
>>> a = StringIO(u"0 1\n2 3")
>>> np.loadtxt(a)
array([[ 0., 1.],
[ 2., 3.]])
In the above code the np.loadtxt() function is used to read the data from the StringIO object 'a' and return it as a NumPy array.
The function takes three arguments:
1.
The input data source: In this case, it's the StringIO object 'a' that contains the data.
2.
The data type: The data type of the output array. In this case, it's not specified, so it defaults to float.
3.
The delimiter: The delimiter used to separate the data in the input source. In this case, it's not specified, so it defaults to any whitespace.
The output of the code is a 2D NumPy array with two rows and two columns of data, as specified in the input source.
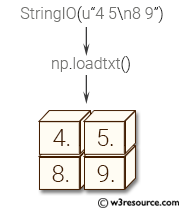
Pictorial Presentation:
Example: Loading structured text data with NumPy
>>> import numpy as np
>>> from io import StringIO
>>> b = StringIO(u"M 45 85\nF 36 47")
>>> np.loadtxt(b, dtype={'names': ('gender', 'age', 'weight'), 'formats': ('S1', 'i4', 'f4')})
array([(b'M', 45, 85.0), (b'F', 36, 47.0)],
dtype=[('gender', 'S1'), ('age', '<i4'), ('weight', '<f4')])
The above code demonstrates loading structured text data into a NumPy array using the loadtxt function with a specified data type. The data is in the form of a string buffer, b, which contains two lines of text with gender, age, and weight information separated by spaces.
The 'dtype' parameter is used to specify the names and formats of the fields in the resulting NumPy array. In this case, the dtype is a dictionary with 'gender', 'age', and 'weight' as the field names and 'S1', 'i4', and 'f4' as the corresponding data types for each field.
The resulting NumPy array has two rows corresponding to the two lines of text data and three columns corresponding to the three fields specified in the dtype. The first column contains the gender information, represented as a one-byte string ('S1'), while the second and third columns contain integer and floating-point values, respectively.
Python - NumPy Code Editor:
PREV : fromstring()
NEXT : Numerical ranges arange()